学ぶ
![]() 2024.08.02
2024.08.02
![]() ケンゴ
ケンゴ
チームのワークロードを Notion API や Google Calendar API で可視化してみたよ/ unerryインターンレポートvol.8

長期インターン 2 年目に突入したケンゴです。
今回は最近携わったワークロード管理のタスクについてテックブログ風にお届けします。
インターネットで「ワークロード管理」と調べると、「コンピュータが正常なパフォーマンスを保つための管理」といった旨の定義がなされていますが、これはコンピュータに限らず組織や部署、人などにも当てはめることができます。
人単位で見た時に適切な労働時間になっているか、あるタスクに時間がかかりすぎていないか、またはチーム単位で見た際に打ち合わせが多すぎないか、適切なリソース配分ができているか、などパフォーマンスの安定化・効率化のためには適切なモニタリングの仕組みが欠かせません。
特に私の所属している AI&データサイエンスチームではビジネスシーズ開発やデータ価値化ロジックの開発、高度分析や予測案件対応、新規技術開発など幅広い業務を担当しており、チーム全体で Notion を使ってタスク管理(およびナレッジシェア)を行なっています。ワークロードとタスク管理を同時に行えるツールもありますが、全社的に Notion をナレッジシェアのコアに置いていること、タスクのカテゴリ管理もチームによって異なることなどから、独自にワークロード管理の仕組みを構築することにしました。
組織ごとにワークロードおよびタスク管理のやり方はそれぞれあると思いますが、1つの選択肢としてご紹介できればと思います。
何ができる?
最初にアウトプットのイメージからお伝えします。 BigQuery に保存されたテーブルを結合して結果を集計し、Tableau で可視化します。これを週次・月次の定例などでチェックをし、アクションやプロジェクトアサインの改善に繋げています。
よくある上司からの「何にどれだけ時間かけてるの?」「ちゃんと働いてる?働きすぎてない?」という問いにも定量的に回答することができます。 ワークロードが可視化されると、皆が同じ指標で確かめることができるので、今後どうしていけば良いかという改善に繋げやすいですよね。
分析の一部の例を紹介します。
1.ワークロードの時系列変化

- ◼︎チームリーダーの稼働を時系列で表示してみました。色分け(青:開発タスク、黄色:Meeting、緑色:イベント登壇など)はタスクカテゴリで、裏側のグレーが合計の作業時間になります。
- ◼︎過剰な残業もなく安定的に推移していることが分かります。ただ、チームリーダーなだけあって、Meeting が約半分以上の時間を占めており、開発に使える時間が限られてしまっている期間が続いていることがわかります。
2.イベントタイプ別
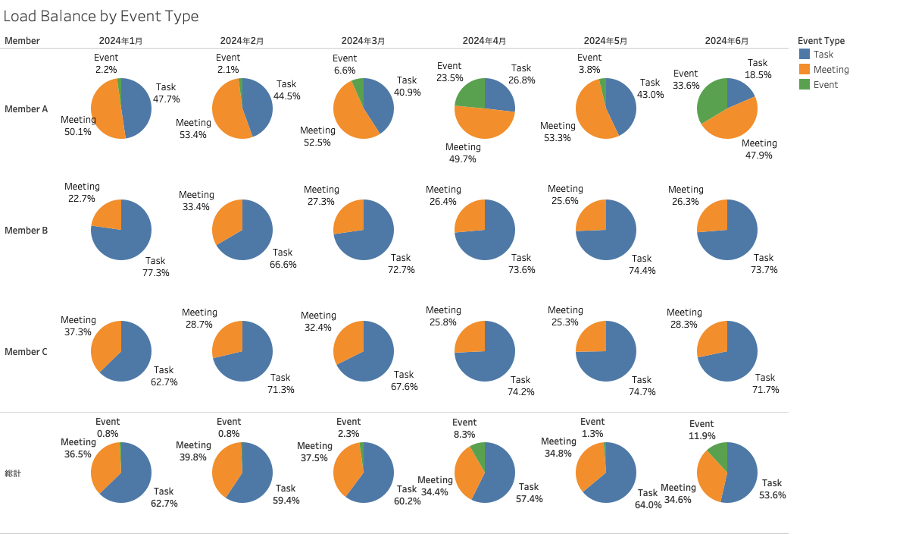
- ◼︎今度はチームから 3 名のメンバーを抜粋して、月別のイベントタイプ(青:開発タスク、黄色:Meeting、緑色:イベント登壇など)ごとの時間配分を表示してみました。一番下は 3 名の総計です。
- ◼︎一番上の Member A は冒頭のチームリーダーのことですが、過去半年ずっとMTGが半分を占めている状態です。また月によってはイベント登壇などで開発工数が圧迫されていることが分かります。
- ◼︎チーム全体では Meeting に掛ける時間を 30% 以下にする目標があり、この分析のおかげで徐々にではありますが下がってきています。
3.プロジェクト カテゴリ別

- ◼︎AI & DS チームでは、プロジェクトを主に、データ開発、ビジネスシーズ開発、R&D、チームビルディングの 4 種に分けています。また、それぞれの配分目標値をそれぞれ 60%、15%、20%、5% と立ててバリューの最適化を図っています。
- ◼︎一部のメンバー(と、一番下は総計)のプロジェクト カテゴリ別の時間配分を算出してみた結果、人によってばらつきはありますが、チーム全体としては安定するようになってきました。ただ目標とする配分とのズレはあるため、ここをどう改善していくかが今後の課題です。
このようにワークロードを可視化・分析することで、どこにどれくらいの時間をかけているか、バランスに偏りが生じていないかを知ることができ、改善点が見つかれば次の期間の目標をどう設定しようかという議論ができるようになります。
使っているツールと用途
- ◼︎Google Calendar:タスクやミーティングの時間を記入
- ◼︎Notion:タスク管理、ナレッジシェア 等
- ◼︎Google Cloud
ーBigQuery:データ蓄積
ーCloud Functions:データ収集関数
ーCloud Pub / Sub:関数トリガー
ーCloud Scheduler:トリガー スケジューラ - ◼︎Tableau:可視化分析
全体のアーキテクチャ図

Notion と Google Calendar の説明
主に扱うデータソースは Notion と Google Calendar です。Notion におけるタスク管理データは、プロジェクト / イシュー の階層構造になっており、別々のデータベースに格納されているため、それぞれ取得する必要があります。 プロジェクトに紐づいた主な情報には
- ◼︎一意的に割り振られたプロジェクトID
- ◼︎プロジェクト名
- ◼︎プロジェクトカテゴリ
- ◼︎進捗ステータス
などがあります。 また、イシューに紐づいた主な情報には
- ◼︎一意的に割り振られたイシューID
- ◼︎イシュー名
- ◼︎(紐づいている)プロジェクト名
- ◼︎開発担当者
- ◼︎レビュワー
- ◼︎進捗ステータス
などがあります。ここに含まれるプロジェクト名を使用してプロジェクトテーブルと結合させることで、誰がどのイシューを現在担当しているか、どの業務カテゴリに属するかといった情報を紐づけることができます。
一方で、AI&データサイエンスチームでは Google Calendar を使って個人のスケジュール管理を行い、他のユーザとの共有も行っています。以降、一つの予定のことをイベントと呼びます。 Google Calendar に含まれる主な情報には
- ◼︎イベント名
- ◼︎イベントを登録したユーザ名
- ◼︎イベントの開始時間
- ◼︎イベントの終了時間
があります。また、イベントの登録には以下のルールを設けています。
- ◼︎TSK = タスク、MTG = ミーティング、EVT = イベント(研修や登壇など)、RTN = ルーティン(Notion に紐づかないルーティンタスク)など、ラベルをイベント名に含める。(例 MTG : クライアントA)
- ◼︎イシュー ID をイベント名に含める。
- ◼︎予定は入れておくが、当日の仕事終わりに作業実績に応じてイベントの時間を変更する。
この処理プログラムではまず初めに各データを API を使って取得し、それらを加工してBigQuery(BQ)へアップロードします。この際、あらかじめ Google サービスアカウントを発行し、BQ への書き込み許可の付与や Google Calendar API が利用可能になっているかを確認する必要があります。
またこのプログラムを Google Cloud の Cloud Functions にデプロイし、さらに毎時スクリプトを定期実行させるため、Pub/Sub および Cloud Scheduler を使用します。これらに関しては後ほど詳しく解説します。
Notion API を使ってみた
まずは Notion のデータ取得から解説します。 Notion API を使ってプロジェクトとイシューのデータを別々のスクリプトで取得しています。なお、ここではプロジェクトとイシューの取得方法はおおむね同じであるため、プロジェクトの例を用いて解説します。
予め、Notion API Key、Notion Database ID、BigQuery の宛先情報などを環境変数にセットしておきます。
import requests
import json
import pandas as pd
import os
import numpy as np
import datetime
from google.cloud import bigquery
import google
def main(event,context):
NOTION_API_KEY = os.getenv('NOTION_API_KEY')
DATABASE_ID = os.getenv('DATABASE_ID')
loop_cnt = 0
has_more = True
data_project = []
while has_more:
loop_cnt += 1
url = '<https://api.notion.com/v1/databases/>' + DATABASE_ID + '/query'
headers = {
'Notion-Version': '2022-06-28',
'Authorization': 'Bearer ' + NOTION_API_KEY,
'Content-Type': 'application/json',
}
payload = {'page_size': 100} if loop_cnt == 1 else {'page_size': 100, 'start_cursor': next_cursor}
r = requests.post(url, headers=headers, data=json.dumps(payload))
data_project += r.json().get('results')
has_more = r.json().get('has_more')
next_cursor = r.json().get('next_cursor')
contents_project = [i['properties'] for i in data_project]
df_project = pd.DataFrame(contents_project)
def get_property_values_project(d):
property_type = d.get("type")
if property_type == 'people':
try:
names = []
if len(d[property_type])==0:
return None
else:
for i in d[property_type]:
names.append(i["name"])
return np.array(names)
except:
return None
elif property_type == "multi_select":
return None
elif property_type == "select":
try:
return d[property_type]["name"]
except:
return None
elif property_type == "unique_id":
try:
return str(d[property_type]["number"])
except:
return None
elif property_type == "rich_text":
try:
return d[property_type]["plain_text"]
except:
return None
elif property_type == "rollup":
try:
return str(d[property_type]["number"])
except:
return None
elif property_type == "title":
try:
return d[property_type][0]["plain_text"]
except:
return None
elif property_type == "status":
try:
return d[property_type]["name"]
except:
return None
elif property_type == "date":
try:
return str(d[property_type])
except:
return None
elif property_type == "relation":
try:
if len(d[property_type])==0:
return None
else:
title = []
for j in d[property_type]:
page_id = j["id"]
url = '<https://api.notion.com/v1/pages/>' + page_id +"/properties/title"
headers = {
'Notion-Version': '2022-06-28',
'Authorization': 'Bearer ' + NOTION_API_KEY,
'Content-Type': 'application/json',
}
r = requests.get(url, headers=headers)
title_list = r.json().get('results')
for k in title_list:
title.append(k["title"]["plain_text"])
return np.array(title)
except:
return None
df_project = df_project.applymap(get_property_values_project)
df_project.rename(columns={
"ID":"project_id",
"Project name":"project_name",
"Watcher":"watcher",
"Category":"category",
"Phase":"phase",
"Issuer":"issuer",
"Status":"status",
"Priority":"priority",
"Duration":"duration",
"Is Blocking":"is_blocking",
"Blocked By":"blocked_by"
,inplace=True)
scope=["<https://www.googleapis.com/auth/cloud-platform>"]
credentials, project = google.auth.default(scopes=scope)
client = bigquery.Client(credentials=credentials)
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("project_id", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("project_name", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("watcher", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
bigquery.SchemaField("category", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("phase", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("issuer", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
bigquery.SchemaField("status", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("priority", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("duration", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("is_blocking", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
bigquery.SchemaField("blocked_by", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
],
write_disposition="WRITE_TRUNCATE",
)
dataset_ref = client.dataset('xxxxx', project = 'xxxxx')
table_ref = dataset_ref.table('xxxxx')
job = client.load_table_from_dataframe(
df_project, table_ref, job_config=job_config
)
job.result()
return print("process done")
main関数の中身を切り分けて解説していきます。
NOTION_API_KEY = os.getenv('NOTION_API_KEY')
DATABASE_ID = os.getenv('DATABASE_ID')
Notion APIを使用する際は予め Notion インテグレーションキー Notion_API_KEY と 集計したい Notion データベースID DATABASE_ID を取得しておく必要があります。
インテグレーションキーとはあるユーザが Notion に API 経由でアクセスする際にアクセス権限を確認するための鍵のことを指します。
データベースID は Notion のそれぞれのテーブルに対応するIDとなっており、参照するテーブルが違う場合はこのIDも変える必要があります。そのため、プロジェクトのデータを取得する作業とイシューのデータを取得する作業とではIDが異なります。
loop_cnt = 0
has_more = True
data_project = []
while has_more:
loop_cnt += 1
url = '<https://api.notion.com/v1/databases/>' + DATABASE_ID + '/query'
headers = {
'Notion-Version': '2022-06-28',
'Authorization': 'Bearer ' + NOTION_API_KEY,
'Content-Type': 'application/json',
}
payload = {'page_size': 100} if loop_cnt == 1 else {'page_size': 100, 'start_cursor': next_cursor}
r = requests.post(url, headers=headers, data=json.dumps(payload))
data_project += r.json().get('results')
has_more = r.json().get('has_more')
next_cursor = r.json().get('next_cursor')
contents_project = [i['properties'] for i in data_project]
df_project = pd.DataFrame(contents_project)
こちらでは実際に Notion API を使ってデータを取得しています。なおこの部分はこちらのサイトを参考に作成させていただきました。流れとしては API リクエストを送信し、そのリターンとして JSON ファイルを取得して保存するという形になっています。
Notion API では一回のリクエストで得られるページ数(行数)は最大で100のため、行数が100以上の場合は101番目以降のデータは取得できないことになり、このような状況を検知するために、has_moreというプロパティがあります。
この値がtrueの場合は101番目以降のデータが存在することを示していて、next_cursor プロパティに101番目以降のデータが格納されている場所の情報が格納されています。そのため、has_more が false になるまで while 文でループを回しています。
その後取得した情報をデータフレームに格納して保存しています。
def get_property_values_project(d):
property_type = d.get("type")
if property_type == 'people':
try:
names = []
if len(d[property_type])==0:
return None
else:
for i in d[property_type]:
names.append(i["name"])
return np.array(names)
except:
return None
elif property_type == "multi_select":
return None
elif property_type == "select":
try:
return d[property_type]["name"]
except:
return None
elif property_type == "unique_id":
try:
return str(d[property_type]["number"])
except:
return None
elif property_type == "rich_text":
try:
return d[property_type]["plain_text"]
except:
return None
elif property_type == "rollup":
try:
return str(d[property_type]["number"])
except:
return None
elif property_type == "title":
try:
return d[property_type][0]["plain_text"]
except:
return None
elif property_type == "status":
try:
return d[property_type]["name"]
except:
return None
elif property_type == "date":
try:
return str(d[property_type])
except:
return None
elif property_type == "relation":
try:
if len(d[property_type])==0:
return None
else:
title = []
for j in d[property_type]:
page_id = j["id"]
url = '<https://api.notion.com/v1/pages/>' + page_id +"/properties/title"
headers = {
'Notion-Version': '2022-06-28',
'Authorization': 'Bearer ' + NOTION_API_KEY,
'Content-Type': 'application/json',
}
r = requests.get(url, headers=headers)
title_list = r.json().get('results')
for k in title_list:
title.append(k["title"]["plain_text"])
return np.array(title)
except:
return None
df_project = df_project.applymap(get_property_values_project)
df_project.rename(columns={
"ID":"project_id",
"Project name":"project_name",
"Watcher":"watcher",
"Category":"category",
"Phase":"phase",
"Issuer":"issuer",
"Status":"status",
"Priority":"priority",
"Duration":"duration",
"Is Blocking":"is_blocking",
"Blocked By":"blocked_by"
,inplace=True)
先ほどデータフレームに格納した結果はすべて辞書形式になっており、この中から必要な情報を抽出する必要があります。上記のコードは各列の辞書形式のデータから必要な情報を抽出するための関数となっています。それぞれのケースについて解説は避けますが、やっていることとしてはそれぞれの列の辞書データには property_type という情報が含まれており、この値によって辞書データの構造が決まっているため、property_type の値によって場合分けを行うことで必要な情報を抽出しています。
最後に applymap 関数を使って列ごとに関数を適用させて必要な情報の部分のみを抽出し、その後、列名を任意のものに変更しています。Notion APIを使った作業はここまでで、この後は BQ へのアップロード処理です。
scope=["<https://www.googleapis.com/auth/cloud-platform>"]
credentials, project = google.auth.default(scopes=scope)
client = bigquery.Client(credentials=credentials)
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("project_id", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("project_name", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("watcher", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
bigquery.SchemaField("category", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("phase", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("issuer", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
bigquery.SchemaField("status", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("priority", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("duration", bigquery.SqlTypeNames.STRING),
bigquery.SchemaField("is_blocking", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
bigquery.SchemaField("blocked_by", bigquery.SqlTypeNames.STRING,mode="REPEATED"),
],
write_disposition="WRITE_TRUNCATE",
)
dataset_ref = client.dataset('xxxxx', project = 'xxxxx')
table_ref = dataset_ref.table('xxxxx')
job = client.load_table_from_dataframe(
df_project, table_ref, job_config=job_config
)
job.result()
return print("process done")
ここからは BQ へテーブルをアップロードする作業です。まず初めに scope で権限を与える範囲を指定し、client インスタンスを作成します。
job_config の内部ではアップロードするテーブルのスキーマ定義を行っており、その中のSqlTypeNames ではそれぞれの列に対して適切な型を指定しています。 mode を指定することでカラム属性を指定することができます。今回の場合、一つのイシューにアサインされている人が複数名存在する場合があるため、複数の値が想定される列(リスト型)に対してはmode = ”REPEATED” と指定することでBQ上で配列として格納することができます。
write_disposition では、アップロード先にすでにデータが存在する場合どのような挙動にするかを指定します。今回は毎時実行時に全てのデータを書き換えるという要件であったため、”WRITE_TRUNCATE” を指定しました。このほかにも、先にアップロードされているものがある場合は更新をしない設定や追加する設定もあるので用途によって使い分けが必要です。
その次の 3 行ではアップロード先のプロジェクト名やデータセット名、テーブル名を指定しています。
Google Calendar APIを使ってみた
続いては Google Calendar データの取得について解説します。
import datetime
import re
import pandas as pd
import numpy as np
import google.auth
from googleapiclient.discovery import build
from google.cloud import bigquery
import googleapiclient.discovery
import google.auth
def main(event,context):
scope_calendar = ['<https://www.googleapis.com/auth/calendar>']
scope_bq = ["<https://www.googleapis.com/auth/cloud-platform>"]
credentials_calendar, project_calendar = google.auth.default(scopes=scope_calendar)
credentials_bq,project_bq = google.auth.default(scopes=scope_bq)
client = bigquery.Client(credentials=credentials_bq)
calendar_id = ['xxxxxxx',"xxxxxxx","xxxxxxx"]
service = googleapiclient.discovery.build('calendar', 'v3', credentials=credentials_calendar)
d = datetime.date.today()+ datetime.timedelta(days=7)
max = datetime.datetime(year=d.year, month=d.month, day=d.day, hour=23, minute=59, second=00).isoformat()+"Z"
calendar = []
for id in calendar_id:
event_list = service.events().list(
calendarId=id, timeMax=max,timeMin="2024-01-01T00:00:00Z",
singleEvents=True,
maxResults=3000,
orderBy='startTime').execute()
events = event_list.get('items', [])
for i,event in enumerate(events):
try:
event_start = event["start"]["date"]
event_start = datetime.datetime.strptime(event_start, '%Y-%m-%d')
event_start = datetime.datetime.combine(event_start, datetime.time())
event_end = event["end"]["date"]
event_end = datetime.datetime.strptime(event_end, '%Y-%m-%d')
event_end = datetime.datetime.combine(event_end, datetime.time())
except:
event_start = event["start"]["dateTime"]
event_start =datetime.datetime.strptime(event_start, '%Y-%m-%dT%H:%M:%S+09:00')
event_end = event["end"]["dateTime"]
event_end = datetime.datetime.strptime(event_end, '%Y-%m-%dT%H:%M:%S+09:00')
duration = round((event_end-event_start).total_seconds())/60
try:
title = event["summary"]
except:
title = None
calendar.append([id,title,event_start,event_end,duration])
# print(i)
df_calendar = pd.DataFrame(calendar,columns=["user","event_name","event_start","event_end","event_duration"])
df_calendar["event_duration"] = df_calendar["event_duration"].astype("int64")
job_config=bigquery.LoadJobConfig(
schema = [
google.cloud.bigquery.SchemaField("user",bigquery.SqlTypeNames.STRING),
google.cloud.bigquery.SchemaField("event_name", bigquery.SqlTypeNames.STRING),
google.cloud.bigquery.SchemaField("event_start", bigquery.SqlTypeNames.DATETIME),
google.cloud.bigquery.SchemaField("event_end", bigquery.SqlTypeNames.DATETIME),
google.cloud.bigquery.SchemaField("event_duration", bigquery.SqlTypeNames.INTEGER)
],
write_disposition="WRITE_TRUNCATE",
)
dataset_ref = client.dataset('xxxxx', project = 'xxxxx')
table_ref = dataset_ref.table('workload_calendar_events')
job = client.load_table_from_dataframe(
df_calendar, table_ref, job_config=job_config
)
job.result()
return print("process done")
今回も main 関数の中身を切り出して解説していきます。
scope_calendar = ['<https://www.googleapis.com/auth/calendar>']
credentials_calender, project_calendar = google.auth.default(scopes=scope_calendar)
calendar_id = ['xxxxxxx',"xxxxxxx","xxxxxxx"]
service = googleapiclient.discovery.build('calendar', 'v3', credentials=credentials_calendar)
d = datetime.date.today()+ datetime.timedelta(days=7)
max = datetime.datetime(year=d.year, month=d.month, day=d.day, hour=23, minute=59, second=00).isoformat()+"Z"
この部分では主に権限関連の処理を行っています。
scope_calendar では Google Calendar へのアクセスのスコープを指定しています。
calendar_id には抽出したいイベントの対象ユーザを指定しています。リスト形式になっているため、複数のユーザを指定することが可能です。 最後の2行では日時をしています。本タスクにおける要件として現在から 7 日先の 23:59 までのイベントを取得するというものだったので、.today() で当日の日付を取得したのちに timedelta で 7 日先の日付を取得しています。その後、23:59 を指定するために datetime.datetime を使用しています。
calendar = []
for id in calendar_id:
event_list = service.events().list(
calendarId=id, timeMax=max,timeMin="2024-01-01T00:00:00Z",
singleEvents=True,
maxResults=3000,
orderBy='startTime').execute()
ここでは calendar_id に指定したユーザごとに、指定した期間内のイベントデータを取得しています。ここでは実際にイベントを取得するのは service.events().list() が担っています。この中では maxResults と呼ばれるパラメータを指定することができ、これは 1 回のリクエストにつき、返されるイベントの最大数となっています。この値は省略可能ではありますが、デフォルトは 250 となっているため、1 回のリクエストで多くのイベントを取得する必要がある際は明示的に指定する必要があります。
events = event_list.get('items', [])
for i,event in enumerate(events):
try:
event_start = event["start"]["date"]
event_start = datetime.datetime.strptime(event_start, '%Y-%m-%d')
event_start = datetime.datetime.combine(event_start, datetime.time())
event_end = event["end"]["date"]
event_end = datetime.datetime.strptime(event_end, '%Y-%m-%d')
event_end = datetime.datetime.combine(event_end, datetime.time())
except:
event_start = event["start"]["dateTime"]
event_start =datetime.datetime.strptime(event_start, '%Y-%m-%dT%H:%M:%S+09:00')
event_end = event["end"]["dateTime"]
event_end = datetime.datetime.strptime(event_end, '%Y-%m-%dT%H:%M:%S+09:00')
duration = round((event_end-event_start).total_seconds())/60
try:
title = event["summary"]
except:
title = None
calendar.append([id,title,event_start,event_end,duration])
# print(i)
df_calendar = pd.DataFrame(calendar,columns=["user","event_name","event_start","event_end","event_duration"])
df_calendar["event_duration"] = df_calendar["event_duration"].astype("int64")
APIリクエストにて取得したイベントデータは辞書形式のデータとして保存されており、その中でも必要な情報は items プロパティに格納されています。また、複数イベントを取得したため、それらの情報はリスト形式となっているため、for 文を使って処理を行っています。イベントによって日付のみを登録している場合と日時を指定している場合が確認されたため、例外処理を使ってそれぞれを処理しました。最後にこれらの値をデータフレームに保存しています。
BQ へのアップロードは Notion データ取得とほぼ変わらないため省略します。
関数のデプロイ
ここまでで作成した関数を使用するには任意の環境にて実行する必要があります。そこで今回は Google Cloud から提供されている以下のサービスを使用します。
- ◼︎Cloud Functions
- ◼︎Cloud Pub/Sub
- ◼︎Cloud Scheduler
Cloud Functions とは関数をサーバレスな環境で実行できる Google Cloud のサービスです。通常、関数を実行する際は実行環境のサーバ構築・保守が必要となるため、多大なるコストがかかります。一方でサーバレス環境である Cloud Functions ではサーバ構築・保守はすべて Google Cloud が担うため、開発者は関数やアプリケーションの開発のみに注力することができます。
ただ、ここにデプロイしただけでは自動的に実行される機能はなく、手動で実行ボタンを押す必要がありますが、そこは自動的に実行させたいですよね。そこで登場するのが Cloud Pub/Sub というサービスと Cloud Scheduler です。
Cloud Functions の実行は様々なトリガーを元に自動的に行うことができ、そのうちのひとつに Cloud Pub/Sub があります。このトリガーでは Cloud Pub/Sub にメッセージが送信されたタイミングで Cloud Functions 上の関数を実行するようになっています。そしてこのメッセージを定期的に送る仕組みが Cloud Scheduler です。Cloud Scheduler が定期的に Cloud Pub/Sub へメッセージを送信させる指示をすることによって、人の手を介さずに自動的に関数を実行する仕組みが完成します。
ここまでの流れをまとめると以下の図のようになります。  出典: Cloud Functionsを定期実行する https://zenn.dev/renn/articles/ee6fabe2cf5b25 この設定が完了すると定期的に関数が自動で実行され、BQ 上のテーブルも自動的に更新されるようになります!
出典: Cloud Functionsを定期実行する https://zenn.dev/renn/articles/ee6fabe2cf5b25 この設定が完了すると定期的に関数が自動で実行され、BQ 上のテーブルも自動的に更新されるようになります!
まとめ
ここまでワークロード管理を行うためのデータ収集について解説してきました。
この作業を通じて Notion API と Google Calendar API の使い方を習得できたとともに、Cloud Functions の使い方も一部ではありますが習得することができました。ですが、Cloud Functionsにはまだまだ多くのサービスが存在するため、今後も様々なタスクをこなすことで Google Cloud との距離も縮められたらいいなと考えています!
インターンは現在も募集中!! ご興味いただけた方はぜひインターン募集ページよりご応募ください!(うねりの泉編集部)
この記事を書いたのは
-

-
ケンゴ 記事一覧
unerryでインターン中の横浜市立大学データサイエンス研究科修士1年。趣味はメジャーリーグ観戦と楽器演奏(ジャズバンドやってます)
SHARE THIS ENTRY
-
 0
0
-
 0
0
-
 0
0
-

ABOUT
「うねりの泉」は、「リアル行動データ」活用のTipsやお役立ち情報、そして会社の文化や「ひと」についてなど、unerryの"とっておき"をご紹介するメディアです。


