学ぶ
![]() 2022.06.22
2022.06.22
![]() Yuki
Yuki
60時間かけて標高データ整備に取り組んだら Python さんとの距離も縮んだよ / unerryインターンレポートvol.2

unerryインターンのYukiです。
今回は、unerryが持っている位置情報データを有効活用すべく取り組んだ、「標高データ整備プロジェクト」についてレポートします。

「標高データ整備プロジェクト」のはじまり
unerryが提供している施設来訪者分析サービスでは、来訪者を正しく捉えることが重要ですが、複数階ある建物だと別の施設の来訪者まで同時にカウントしてしまう可能性があります。
そのため、通常は正確に来訪判定ができるビーコンの設置をお願いするのですが、どうしても設置ができないケースではGPSログから来訪を推測することになります。しかし、GPSから取得できる高さ情報は建物内では誤差が大きいため、GPSだけではこの問題を解決することはできません。
そこでunerryではビーコンログを正解データとして、建物形状や移動ベクトルなどを考慮しながらGPSログを補正し、来訪判定の高精度化を行っています。
これまでは個別の案件でデータアナリストが分析しながら補正を行っていましたが、案件の増加に伴い汎用的なロジックの開発が必要となりました。高さを考慮した来訪判定の高精度化に向けた第一歩として、まずはGPSから取得できる高さ情報の基準をある一定のものに合わせながら、地表面の高さに変換できるようにすることを目標としてこのプロジェクトは始まりました。
「標高データ整備」の3ステップ
ステップ1 基準点の調整
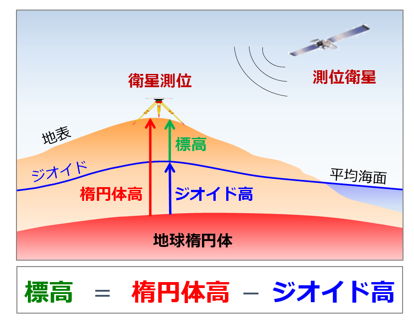
出典:国土地理院ウェブサイト (https://www.gsi.go.jp/buturisokuchi/grageo_geoid.html)
ユーザーのスマートフォンから得られる「高さ」データは、AndroidとiOSでそれを計測する基準点が異なります。図で言うと、前者は楕円体高ベース、後者は標高ベース(平均海面ベース)のものになっています。
楕円体高というのは、回転楕円体という、楕円を地軸(北極と南極を結ぶ線)で回転させて出来た仮想的な立体の面から地表までの距離のことを指しています。
(参考 https://qzss.go.jp/overview/column/geoid_151225.html )
そのため、まずは両者の「高さ」の基準点を標高ベースに合わせることとし、上の図にあるようにAndroidの元の高さのデータである“楕円体高”から“ジオイド高”を引きます。ジオイド高のデータは、国土交通省が公開しているジオイド・モデルが Python で扱えるようにまとめられたものを使いました。(https://github.com/naokiueda/EllapsoidToElevation )
ステップ2 地表面の標高データの収集と前処理
次のステップでは、“標高ベースに揃ったデータ”から“標高(図の緑色の、平均海面から地上までの高さ)”を引きます。こうすることで「高さ」を表すオリジナルのデータが「地面からGPSログまでの高さ」のデータになります。
ただ、このステップが結構大変でした。国土交通省が公開している全国の標高データ(https://fgd.gsi.go.jp/download/menu.php )はxml形式のファイルで、その中身は緯度経度の始点・終点とそのエリアに対応した標高値が羅列されたものでした。
xmlファイルを見るのも扱うのも初めてだったので、どんな操作をすれば良いのか最初は見当もつきませんでしたが、試行錯誤するうちに Python にはxmlファイルの中身を読み込む機能があることがわかりました。そして、xmlファイルの数値がどのような規則で並んでいるかをファイル仕様書から知り、羅列された数値を規則に沿って適切に並び変える機能を追加することでPythonに読み込むことができました。
第一の壁を乗り越えた先に早速現れたのは第二の壁…というよりは思わぬ落とし穴で、 Python コードを実行し BigQuery にテーブルを作成する作業中に引っかかりました。
BigQuery にアップロードしたテーブル上の標高値が正しいかチェックした際、数値が微妙に正解の値からずれていることに気づきました。そこでファイルの一覧を見ていると他のファイルと比べてサイズが小さいものがいくつかあることが判明し、「妙だな…」と思い中身を見てみると通常であれば33,750件あるはずの標高値が、33,750未満の件数しか含まれていませんでした!
収集したデータは、中身が欠けている(厳密には、県境や海、測定不可能な地点のため観測値が除外されていました)可能性を疑い、必ず事前にチェックするべきでした。標高値が欠損したままでは緯度経度と標高値の対応関係がずれてしまうため、欠損部分にはダミー値として-9999を補填してズレを修正するコードを追加する処理を行いました。
このことは、段階を踏んでミスがないかチェックすることや、元データの前処理をしっかりとすることがデータ整備においてどれほど重要であるかを実感する良い経験になりました。
ステップ3 BigQuery でのデータ整備
このステップでは上の2ステップで地域ごとに細かくアップロードしたデータを BigQuery 上で統合したり、テーブル上の数値を使って計算を行うクエリを書くことで元のデータを「 BigQuery で利用可能なデータ」にする作業を行いました。
今回のタスクで Python の次によく使ったのは BigQuery ですが、個人的に BigQuery は Python よりも難解なイメージがあります。実際に一番難しかったのは BigQuery でのタスクで、各緯度経度に対応するジオイド高を BigQuery 上で計算するコードを書くというものでした。
私のスキルでは歯が立たなかったため共同でタスクを進めている方に助けていただいたのですが、出来上がったコードは理解こそできたものの、自力で書きあげるには厳しいコードで、レベルの差を見せつけられました(笑)
以上の3ステップを通し、苦労して作成した全国の標高データのテーブルのサイズは、約344GB!
私のiPhoneの容量以上のデータサイズです(笑)
まとめ
今回のタスクは合計60時間程度かかりました。主に使用したツールは Python 、 BigQuery 、 Tableau (結果を可視化するダッシュボードツール)です。
「標高データを整備して位置情報データを有効活用できるようにする基盤づくり」という目標に向かってタスクを進めていきましたが、ここでは書ききれない大変なことが多くありました。自分がやっている作業は正しいのか、トンチンカンな事をやっていないかなど不安になったり、扱ったことのないデータ形式やツールが出てくるとその度に足止めを食らったり。
ただ、そんな分からないことだらけの中でも色々調べ、聞き、実践してみることで着実に自分が成長していることに気づいた時はやはり嬉しいですし、特に Python に関しては自分が考えていることをうまく実装できると Python と自分が会話できているような気がしてとても楽しいです!
unerryでのインターンを考えている方や、unerryのデータサイエンスを扱う仕事に興味があるけど、「ちょっと不安だ」という方、大丈夫です!
自ら学ぶ姿勢さえあれば、私たちと一緒に様々なタスクやプロジェクトに挑戦する中で、位置情報や人流データをはじめとするビッグデータを扱うための Python や SQL 、 Tableau 等の知識やスキルは自然と身について来るはずです。(実際経験ゼロだった私もそうでした。)
と色々語りましたが、私自身の知識やスキルもまだまだ未熟なので、今後も様々なタスクを通してスキルアップしていこうと思います!
インターンは現在も募集中!!
ご興味いただけた方はぜひインターン募集ページよりご応募ください!(うねりの泉編集部)
この記事を書いたのは
-

-
Yuki 記事一覧
unerryでインターン中の慶應義塾大学 総合政策学部に在学中の3年生。データサイエンティストを目指してプログラミングやデータ分析について勉強中。趣味はアニメ鑑賞と対戦ゲーム、eスポーツの大会観戦。アイコンは我が家の愛犬のトイプードル、モコです。
SHARE THIS ENTRY
-
 0
0
-
 0
0
-
 0
0
-

ABOUT
「うねりの泉」は、「リアル行動データ」活用のTipsやお役立ち情報、そして会社の文化や「ひと」についてなど、unerryの"とっておき"をご紹介するメディアです。


